
INTRODUCTION
MANY composers have used various devices intended to evoke laughter or amusement among listeners (e.g. Gruneberg, 1969; Moore & Johnson, 2001; Mull, 1949; Walton, 1993). Haydn, in particular, is noted for his various humorous passages (see Wheelock, 1992). For example, in his "Joke Quartet" (Opus 33, No. 2), Haydn makes use of cadential conventions to lure listeners into thinking that the ending has occurred at several different moments, and then actually ends the work on a tonic moment that would normally presage continuation. In modern times, musical humorists, like Peter Schickele (alias PDQ Bach), have made use of a variety of techniques whose purpose is to evoke audience laughter (Huron, 2004, 2006).
An important distinction is generally made between evoked (or induced) emotion, and portrayed (or represented) emotion. Musical passages (such as those produced by Haydn and Schickele) might evoke laughter without necessarily representing laughter. However, it is also possible for a passage to portray laughter (sound laughter-like) without necessarily evoking laughter in listeners. For the purposes of this study, our focus is solely on represented or portrayed laughter in music. That is, our study is concerned with laughter-like passages rather than laughter-inducing passages.
Acoustical features of human laughter have been described by Bickley and Hunniccutt (1992), Provine (2000), and Bachorowski, Smoski, and Owren (2001). Most notably, laughter exhibits an isochronous sequence of punctuated, vocalized exhalations. If the laughter is muted or subdued, the mouth may remain closed. However, the more prototypical laughter involves an open mouth, resulting in a series of vocalized "ha" syllables. In the research literature, each "ha" is referred to as a "call".
In the open-mouth form, laughter is also typically accompanied by smiling which is known to produce audible changes in vocalization (Lasarcyk & Trouvain, 2008; Schröder, et al., 1998). Specifically, smiling involves retraction of the zygomatic muscles, which tend to pull the flesh taut against the teeth, shortening the overall vocal tract length and so raising the frequencies of the F2 and F3 formants (Tartter, 1979, 1980; Tartter & Braun, 1994). In general, a smiling voice sounds brighter.
Although laughter is characterized by both spectral and dynamic changes, it is the temporal pattern (isochronous punctuated calls) that provides the most salient distinguishing feature. Measures of laughter call rates range from 4.37 (Bachorowski, Smoski & Owren, 2001), 4.7 (Bickley & Hunniccutt, 1992), to 5 calls per second (Provine, 2000), with an average of 4.69. In laughter, each vocalized call is followed by a silent period. Measures of the ratio of call-to-silence have been reported as .33 (Provine, 2000), .50 (Bickley & Hunniccutt, 1992), and .57 (Bachorowski, Smoski & Owren, 2001) with an average of .467. Laughter varies notably from person to person, however none of the existing studies provide measures of variance. If certain musical passages are intended to emulate human laughter, one might predict that the music would tend to imitate these temporal parameters.
The idea that laughter might be portrayed musically using a sequence of short repetitive articulations is hardly new. Vladimir Jankélévitch (1961), for example, spoke of "the humor of pizzicatos." Indeed, a quick sequence of pizzicatos does seem to resemble the punctuated exhaling characteristic of laughter.
Inspired by Jankélévitch's observation, this study aims to test formally the hypothesis that musically humorous passages resemble the sound of human laughter—notably the temporal pattern of calls. Specifically, we report two experiments (part one and part two) that address this issue using contrasting methods. In the first experiment, listeners use the method of adjustment to modify tone sequences to sound most laughter-like. The second study is a correlational study examining musical scores. To anticipate our results, nominally humorous passages are shown to indeed exhibit a greater likelihood of employing tones with detached articulation (e.g., staccato) reminiscent of laughter. However, compared with control passages, these staccato passages failed to exhibit the isochronous rhythms characteristic of real laughter.
PART ONE
The first part of the current research tested whether laughter-like sounds can be produced with musical instruments. Specifically, we aimed to determine whether listeners can adjust instrument sounds to emulate laughter, and whether these sounds will exhibit similar features to real laughter.
Hypothesis
Specifically, we proposed to test the following two hypotheses:
H1. When instructed to emulate a laughter-like effect, listeners will tend to adjust the tempo of tone sequences to roughly 4.69 notes per second.
H2. When instructed to emulate a laughter-like effect, listeners will tend to adjust the duty cycle (articulation) of tone sequences with a tone-to-silence ratio of roughly 0.467.
Method
In brief, the experiment involved the method of adjustment where participants were instructed to "tune" the tempo and duty cycle of four different repeating sounds to create the most laughter-like effect.
PARTICIPANTS
For this experiment, 25 participants were recruited from the Ohio State University School of Music participant pool. Sixteen were female and nine were male, all between the ages of 18 and 65. Each participant received class credit for participation, and all were enrolled in 2nd year music theory and aural skills.
PROCEDURE
The experiment made use of a custom-built Max/MSP interface (Puckette & Zicarelli, 1990). The interface included a start/stop button, a save button, a volume control, and two sliders per stimuli, one each for adjusting the repetition rate (tempo) and the duty cycle (articulation/sustain). Participants were asked to adjust four different sounds so as to produce the most laughter-like effect. There was no time limit given for making these adjustments. The first sound consisted of a recorded female voice producing a sustained "ha" syllable. The remaining three sounds consisted of recorded tones produced by a bowed cello (pitch C3), a horn (F4), and a flute (F5). The order of presentation of the sounds was the same across all participants. The default setting for the sliders began with the original speed of the recording and a duty cycle of 0.5. The resulting inter-onset interval of the default setting was 1.2 seconds. The tempo and duty-cycle slider positions were reset for each subsequent sound. The exact time each participant took to complete the task was not recorded, however the study was advertised as taking about 5 minutes to complete, which was a reasonably accurate estimate.
INSTRUCTIONS
Participants received the following instructions: "In this experiment, we're interested in what makes something sound like it's laughing. You'll hear a repeating sound that plays over-and-over again. You can turn the sound "on" by clicking the pink button here. You can turn the sound "off" by clicking the pink button again. [demonstrates]. Here you see three sliders. This grey vertical slide on the left [pointing] is the volume control that you can adjust at any time. This blue horizontal slider [pointing] adjusts how fast the sound repeats - that is, the tempo or speed. This yellow horizontal slider [pointing] adjusts how short or long the sound is.
What we want you to do is very simple: For each sound, we want you to adjust the blue and yellow sliders so as to make the sound as laughter-like as possible. Please aim for a "natural" sounding laughter as possible. There will be four different sounds we want you to adjust. When you have adjusted the sliders so that you're happy with the laughter-like quality, click the buttons at the bottom of the page to save and submit your answers. This experiment won't take any more than five minutes.
Do you have any questions?"
Results
Recall that our motivating hypotheses pertain to both the tempo and duty cycle components of laughter-like sounds. First, consider the tempo responses. Figure 1 shows the distribution of tempos for all four target sounds. In addition, the solid, dashed, and dotted lines indicate the mean laughter tempo values as measured in human laughter by Provine (2000) (solid line), Bickley and Hunniccutt (1992) (dashed line), and Bachorowski, Smoski and Owren, (2001) (dotted line). As can be seen, the mean tempo values in calls/second for all four sound sources are very similar: voice (M =3.69, SD = 0.82), cello (M = 3.63, SD = 1.0.), horn (M = 3.66, SD = 1.07), and flute (M = 3.64, SD = 1.22). Paired t-tests between all four sound sources failed to show any significant differences at the 95 percent confidence level. As evident from Figure 1, each of the means of the experimental data appear to fall below all three values for actual human laughter as measured by Provine (2000), Bickley & Hunniccutt (1992), and Bachorowski, Smoski & Owren (2001). This observation is confirmed by a statistical test. Combining the tempo data for all responses, the aggregate mean (M = 3.65, SD = 0.92) falls below the mean of the three human laughter sources (M = 4.69). A one-sample t-test with the average human laughter value treated as a population mean proved significant (t (24) = -5.628, p <0.0001). That is, the tempo values from the experiment are significantly slower than reported values for measured human laughter.
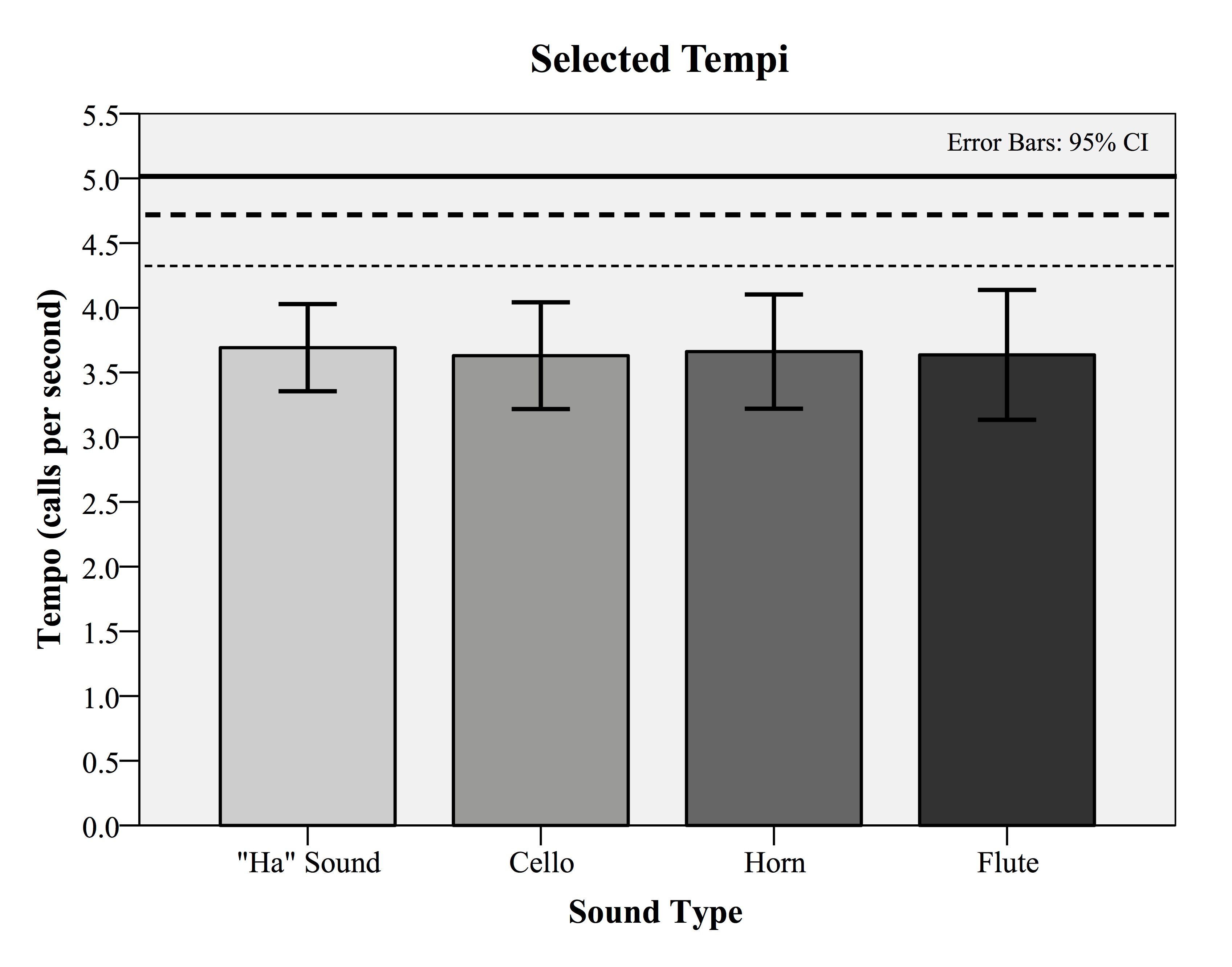
Fig. 1. The mean selected tempi (calls per second/call rate) from a method of adjustment task in which participants were asked to tune vocal and instrumental repeating tones to sound as laughter-like as possible. The resulting mean tempi were significantly slower than previously measured call rates of actual human laughter reported by Provine (2000) (solid line), by Bickley & Hunniccutt (1992) (dashed line), and by Bachorowski, Smoski & Owren (2001) (dotted line).
With regards to duty cycle, the distributions for all four sounds are shown in Figure 2. Once again, there appears to be little difference between the four sound types: voice (M = 0.44, SD = 0.4963), cello (M = 0.45, SD = 0.4977), horn (M = 0.44, SD = 0.4966), and flute (M = 0.43, SD = 0.4957), with M representing the mean of the proportions of sound. Duty cycle values in actual human laughter are reported by Provine (2000) (solid line, mean value = 0.33), by Bickley & Hunniccutt (1992) (dashed line, mean value = 0.50), and by Bachorowski, Smoski & Owren (2001) (dotted line, mean value = 0.57). Combining the duty-cycle data from all stimuli, the aggregate data (M = 0.465, SD = 0.052) falls significantly close to the mean of the Provine, Bickley & Hunniccutt, and Bachorowski et al. values (M = 0.467). A one-sample t-test with the average human laughter duty cycle treated as a population mean proved to not be significant (t (24) = -0.173, p = .864). That is, the duty cycle values from the experiment were comparable to reported values for measured human laughter.
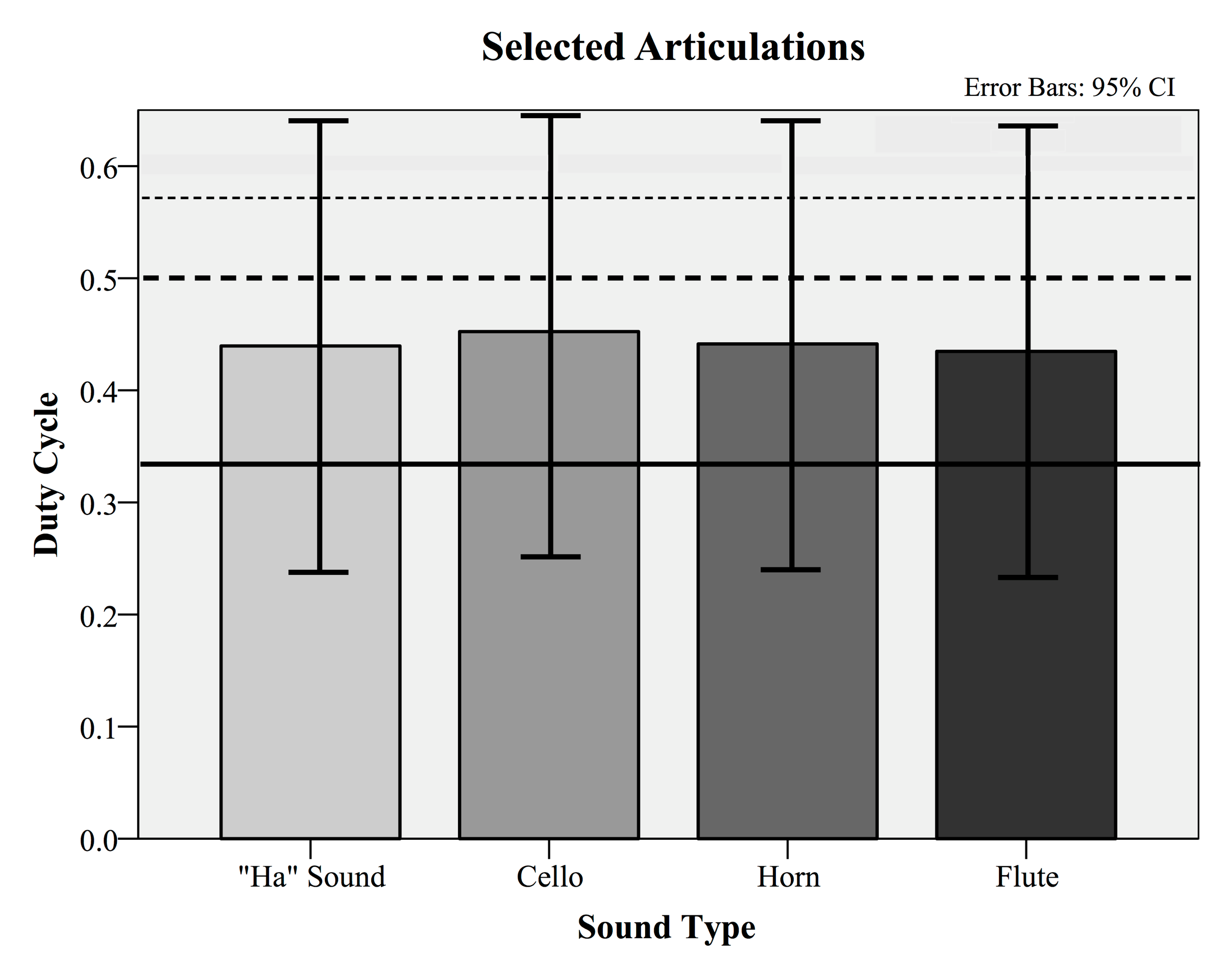
Fig. 2. The mean selected duty cycles (articulations) from a method of adjustment task in which participants were asked to tune vocal and instrumental repeating tones to sound as laughter-like as possible. The resulting mean adjusted duty cycles are comparable to previously measured duty cycles of actual human laughter reported by Provine (2000) (solid line), by Bickley & Hunniccutt (1992) (dashed line), and by Bachorowski, Smoski & Owren (2001) (dotted line).
Discussion
In Part one of the experiment, participants were asked to tune vocal and non-vocal instrumental tones to produce a laughter-like effect using a method of adjustment paradigm. Recall that our first hypothesis was that when instructed to emulate a laughter-like effect, listeners would tend to adjust the tempo of tone sequences to roughly 4.69 notes per second. However, while participants produced call rates that were consistent across the different sound sources, they chose rates that were slower on average than actual laughter rates, inconsistent with our first hypothesis. Our second hypothesis was that when instructed to emulate a laughter-like effect, listeners would tend to adjust the duty cycle (articulation) of tone sequences with a tone-to-silence ratio of roughly 0.467. Our results were consistent with our second hypothesis in that the adjusted sounded portions were comparable to those of actual laughter.
In post-experiment interviews, participants expressed confidence that they were generally successful in completing the task. After having been informed about our hypotheses, many of the participants offered the opinion that the hypotheses are likely true and that musical instruments can be performed in such a way as to resemble human laughter. Some participants commented that they would have liked to be able to adjust the pitch as well as the tempo and duty cycle. They expressed the desire to mimic the downward pitch slope of natural laughter. Perhaps a future study might include that ability in the task.
A few participants commented on the diversity of real laughter, one even suggesting that we had included an example of standardized human laughter. Relatedly, another participant hypothesized that listeners might adjust to what people think sounds like laughter – or essentially a fake representation of laughter, much like how the "smiley face" represents an actual human smile. This prediction might explain why our participants chose rates 22% slower than measures of spontaneous human laughter.
Various observations suggest that fake or staged laughter tends to be slower than normal laughter (Bryant & Aktipis, 2014; Lavan, Scott, & McGettigan, 2016; Provine, 2000; Provine, 2008). Such staged laughter can be found in various operatic recordings. Provine (2000, 2008), for example, examined 20 opera scores for instances of laughter. He measured the musical tempi and duty cycles of the laughter and found similar results to the current study. Remarking on this finding, Provine (2000) has written, "…we found that most composers overestimated the duration of laugh notes ("ha") and inter-note intervals ("ha-ha"). Whether due to artistic constraints (musical context) or perceptual error composers usually made laughter slower (longer) than it really is" (p. 70). Given the potentially fake sound of our looped tones, it could be that participants gravitated towards the slower tempi of staged laughter while making their adjustments, rather than imagining faster genuine laughter.
Another factor likely to influence laughter rate is body size. Rates of respiratory oscillation are strongly related to size (Straub, 1998). Children produce faster laughter rates, whereas large individuals are likely to exhibit a slower ('Santaesque') ho-ho-ho sound. It is possible that musical sounds, or the sounds produced using synthesized envelopes, connote a heavier or larger sound source. Consequently, this would have led our participants to adjust the laughter rate to a slower value that might have been deemed to be more appropriate for the perceived size.
PART TWO
Although the mixed results of part one suggest that musical instrument sounds can theoretically be used to emulate human laughter, these results do not address the question of whether laughter emulation is used in real music making. It would therefore be appropriate to examine actual musical practice.
If a composer intends to create a laughter-like sound, we might expect the passage to exhibit some acoustical features associated with real laughter. However, how do we know that a composer intends to create a laughter-like expression? If laughter-like features are used as a way of identifying candidate laughter passages, the logic would be entirely circular if we argued that laughter-like passages exhibit laughter-like features. This study hinges on the issue of how we might know whether a composer intends to represent or express laughter. While recognizing that we can never be certain of a composer's intentions or aims, there are sometimes telltale signs that suggest that a humorous intention might have possibly motivated the composer. Among such telltale signs is the title of a work. Unfortunately, it is uncommon to find overt titles such as "Columbine is Laughing." However, there exist several genres of music whose origins suggest some overt humorous content, such as Scherzos, badineries and humoresques.
The word "scherzo" is Italian for "jest" or "joke." The word "badiner" is French for "to joke, tease, trifle, or be flippant," with "badinerie" meaning "teasing or childishness." The word "humoresque" derives from the Latin "umor" and has a long and convoluted etymology, mostly related to bodily fluids. The earliest musical use of "humoresque" is attributed to Schumann, who apparently used the term in the historical sense, related to the body humors (Brown, 2001). However, later use of the term in music seems more in keeping with a light-hearted or humorous ethos (Apel, 1969).
Although the origin of these different genres suggests humor or jocularity, it should be noted that not all Scherzos, humoresques or badineries are overtly humorous in tone. In the case of the humoresque, scholars have drawn attention to various melancholic aspects (Kennedy, n.d.), such as those evident in the "Humoresque No. 7" from Dvořák's set of eight Humoresques for piano (Op. 101, 1894).
Accordingly, we cannot claim that any given composition dubbed "Scherzo," "Humoresque" or "Badinerie" is intended to emulate or portray laughter. Rather, our claim is that, as a group, such compositions are more likely to exhibit passages that emulate or portray laughter than other musical works.
If laughter-like features are predicted to be more common in these musical genres, our next question is what features might be consistent with an expression of laughter. As noted earlier, laughter exhibits a series of isochronous puffs or "calls." In notated music, we might expect to see a greater use of staccato or pizzicato, and that any such passages would be more likely to exhibit isochronous rhythms.
For the purposes of our second study, we elected to focus on notated scores. Specifically, we predicted that, compared with similar control works, humoresques/Scherzos/badineries are more likely to contain staccato passages and that sequences of staccato are more likely to be isochronous - consistent with laughter.
Hypothesis
Formally, we proposed to test the following hypotheses:
H3. Compared with similar (non-humoresque/Scherzo/badinerie) passages, humoresques/Scherzos/badineries are more likely to contain staccato sequences.
H4. Compared with similar (non-humoresque/Scherzo/badinerie) passages, staccato passages from humoresques/Scherzos/badineries are more likely to exhibit isochronous rhythms.
Method
MUSICAL SAMPLE
A convenience sample was provided through the International Music Score Library Project (IMSLP) website (Mullin, 2010). A search for the words "humoreseque," "Scherzo", "badineries" uncovered 3,757 works/movements. Most of the identified works were marked Scherzo, somewhat fewer humoreseques, with only a small number of badineries.
In analyzing any musical work, it is necessary to consider what features are simply musical commonplaces before concluding that some feature is characteristic or unique to a given work or genre. Accordingly, this study contrasts each target musical work with a matched control. Specifically, to determine how staccato is used, we must contrast humoresque, Scherzo or badinerie passages with non-humoresque/Scherzo/badinerie passages.
Apart from the conjectured use of staccato to emulate laughter, the use of staccato is apt to be influenced by many other musical concerns. In the first instance, staccato is unlikely to occur in slow musical passages, so it would be inappropriate to compare the use of staccato in humoresque/Scherzo/badinerie passages with works that differ dramatically in tempo. In addition, the use of staccato may vary by musical style, by instrumentation, and by individual composer. Some composers may be more likely to use staccato. Similarly, staccato may be more common for some instruments (e.g., piano), compared with other instruments (e.g., trombone).
Additionally, perhaps it is important to ensure that the control movements are matched for dynamic level. However, the relationship between dynamic level and laughter is not obvious. Laughter itself spans a wide range of loudness levels from quiet giggling to boisterous guffaws. It is not clear that failing to control for dynamic level would bias the results in some way. Given the task of finding matching passages by the same composer, for the same instrument, and at the same tempo, the additional aim of matching dynamic levels was regarded as unduly burdensome. Consequently, we decided a priori not to explicitly match dynamic levels in the controls.
Accordingly, in selecting control passages, the objective was to match each humoresque/Scherzo/badinerie passage with a passage written for the same instrument, written by the same composer, and having the same notated tempo. Musical notation rarely includes detailed metronome markings. Instead, descriptive (Italian) terms are commonplace. These include terms such as Adagio, Andante, Allegro, etc. The target and control works were deemed to exhibit matched tempos if they employed the same tempo term. In many cases, these tempo terms include an adjective or modifier, such as Allegro assai. For the purposes of this study, the modifiers, with the exception of moderato, were ignored. For example, Allegro assai was considered equivalent to Allegro.
In examining the available online materials, nearly two-thirds appeared to consist of solo piano music. To simplify the task of finding matching control passages, we decided to sample only solo piano music. With this instrumentation constraint, a search for the words "humoresque," "Scherzo", "badineries" uncovered 2,684 works/movements; 85% of these movements are "scherzo", 14% are "humoresque", and only a handful (1.2%) are "badineries."
Finally, to reduce the workload to a manageable level, a goal was set a priori of reaching a sample of 300 works – 150 Scherzos/humoresques/badineries and 150 matched control movements. These were the first 150 results from our initial search that fully matched our criteria of containing humoresque, Scherzo or badinerie in the title, were written for solo piano, and for which we were able to find a matched control movement.
| Title: | Control works/movements: |
|---|---|
| Non-form title | 61 (40.7%) |
| Dance | 37 (24.6%) |
| Sonata movement | 10 (6.7%) |
| Prelude | 8 (5.3%) |
| Albumblatter | 7 (4.7%) |
| Caprice | 4 (2.7%) |
| Etude | 4 (2.7%) |
| Arabesque | 3 (2%) |
| Miniature | 3 (2%) |
| Pastorale | 3 (2%) |
| Sketch | 3 (2%) |
| Barcarolle | 2 (1.3%) |
| Fantasia | 2 (1.3%) |
| Rhapsody | 2 (1.3%) |
| Berceuse | 1 (0.7%) |
SAMPLING PROCEDURE
From the randomly ordered list of piano works dubbed humoresque/Scherzo/badinerie, each score was examined to identify whether a tempo marking was present. Several works did not include a tempo designation and so were excluded from the sample. Of the remaining humoreseques/Scherzos/badineries, the tempo designation was determined and a control piano work was sought by the same composer containing the same tempo designation. For some relatively obscure composers, no other piano works were available, and so the target humoreseque/Scherzo/badinerie was discarded from the sample. Having identified candidate piano works by the same composer, the tempo markings were then examined to find a match. As noted above, some leeway was permitted in pairing tempo markings, so that Allegro and Allegro assai were deemed to constitute a matched set. Once again, in several cases, we were unable to find a suitable matched control work/movement, and so the target work was discarded. We continued with this procedure until 300 works were identified - 150 pairs of works matched for composer, instrument, and tempo. Our resulting control movements had titles that were mostly non-form-related (such as character pieces or tempo markings), dances (such as minuets, mazurkas, polkas, etc.), sonata movements, and others (see Table 1).
ANALYSIS PROCEDURE
Having assembled our corpus of matched target and control works/movements, each work/movement was scanned from the beginning for any staccato passages that were at least four notes in succession. If a staccato passage was located, the first such passage was then characterized as having either isochronous (a pattern of consistent lengths occurring at equal intervals) or anisochronous (no pattern of regular lengths and/or occurrences at irregular intervals) rhythms. For example, an isochronous rhythm might consist of an eighth note followed by an eighth note rest that is repeated, whereas an anisochronous rhythm would contain a break in the pattern or notes of unequal lengths (such as a quarter note followed by an eighth note). Notice that a long sequence of notes is statistically less likely to consist of equivalent-duration notes than a short sequence of notes. To avoid confounds introduced by especially long or short staccato passages, the judgment of isochronicity was determined by considering only the first four notes in the relevant passage. That is, if a passage contained 10 successive staccato notes, if the first four notes were equivalent in duration than the passage was operationally deemed "isochronous."
Results
The results are summarized in Table 2. Roughly 78.7 percent of the humoresque/Scherzo/badinerie movements exhibited the presence of at least one staccato passage (of four or more notes in length), whereas only roughly 64.7 percent of the matched control movements included at least one staccato passage. A chi-square test showed that this difference is statistically significant (χ2 (1) = 6.57, p <0.01; with Yates continuity correction applied). The results are consistent with hypothesis 3: that is, humoresque/Scherzo/badinerie movements appear to exhibit more use of staccato.
| Staccato present | Staccato absent | |
|---|---|---|
| Humoresque/Scherzo/badinerie | 118 (78.7%) | 32 (21.3%) |
| Control movements | 97 (64.7%) | 53 (35.3%) |
With regards to hypothesis 4, we examined the initial staccato sequences, 118 from humoresque/Scherzo/badinerie movements and 97 from control movements, for isochronous rhythms. As noted earlier, a passage was deemed to be isochronous if the first four notes of the initial staccato sequence exhibited the same notated duration. The results are shown in Table 3. Roughly 77.8 percent of initial staccato passages in humoresque/Scherzo/badinerie movements exhibited rhythmic isochrony, whereas only roughly 73.8 percent of the initial staccato passages in the matched control movements exhibited isochrony. Despite the skew in the predicted direction, a chi-square analysis found no significant difference between the target and control movements (χ2 (1) = 0.804, p = 0.37; with Yates continuity correction applied).
| Isochronous staccato | Anisochronous staccato | |
|---|---|---|
| Humoresque/Scherzo/badinerie | 93 (78.8%) | 25 (21.2%) |
| Control movements | 82 (84.5%) | 15 (15.4%) |
One might question whether the length of the humoresque/Scherzo/badinerie movements versus the control works may have affected the results. A longer piece is statistically more likely to contain a staccato passage than a shorter piece. Therefore, a post-hoc analysis was conducted to verify whether the humoresque/Scherzo/badinerie movements and their matched control works/movements were of similar lengths. The number of measures in each of the 150 humoresque/Scherzo/badinerie movements and the 150 control movements were counted. The mean number of measures in the humoresque/Scherzo/badinerie movements (M = 172, SD = 163) was higher than the mean number of measures in the control works/movements (M = 128, SD = 106). The difference in length between each of the pairs was calculated. The median difference between the length of the humoresque/Scherzo/badinerie and its paired control work/movement was 10 measures; the distribution was highly varied however, with a standard error of 533 measures. A Wilcoxon-signed-rank test showed that this observed median was significantly higher that the test value of zero (W = 2.477, p < 0.05). In the first instance, it is important to acknowledge that this difference in overall length between the pairs of humoresque/Scherzo/badinerie and matched control works may have confounded our results. On the other hand, the paired differences in length between target and control passages amounts to just six percent.
Conclusion and Discussion
In part one, we asked participants to tune vocal and non-vocal instrumental tones to produce a laughter-like effect. Using the method of adjustment, participants produced call rates that were slower than actual laughter rates. However, consistent with our second hypothesis, participants produced duty cycles that were comparable to actual laughter. These results are somewhat consistent with the suggestion that laughter-like features are recognizable using tones produced by musical instruments. In part two, we examined a body of musical works whose genres suggested that the composer might have had a jocular or humorous musical aim. Compared with matched controls by the same composer, exhibiting the same instrumentation and tempo, it was shown that humoresque/Scherzo/badinerie were more likely to contain staccato sequences, although these sequences were not more likely to exhibit isochronous rhythms. However, post-hoc analyses revealed that the average length of the humoresque/Scherzo/badinerie was significantly longer than matched control movements. This difference in length could result in a higher chance of finding staccato passages in our sample than in the control works and may have confounded our results.
Many scholars have suggested that the capacity of music to express or represent various emotions or affects is attributable to acoustic similarities reminiscent of natural human gestures or expressions, especially vocal expressions. For example, Juslin and Laukka (2003) have reviewed a wide range of research chronicling similarities between musical and vocal expression, such as similarities between sad music and sad vocal expressions. The results of the current studies lend partial support to this view - at least in the case of expressions of human laughter.
ACKNOWLEDGEMENTS
Our thanks to the members of the Cognitive and Systematic Musicology Laboratory at Ohio State University for their critical feedback and support. This article was copyedited by Scott Bannister and layout edited by Kelly Jakubowski.
NOTES
- Correspondence can be addressed to: Caitlyn Trevor, Ohio State University, trevor.5@osu.edu.
Return to Text
REFERENCES
- Apel, W. (1969). Humoresque [G.], humoreske [F.]. In Harvard Dictionary of Music (2nd ed.). Cambridge, MA: The Belknap Press of Harvard University Press.
- Bachorowski, J.-A., Smoski, M.J., & Owren, M.J. (2001). The acoustic features of human laughter. Journal of the Acoustical Society of America, 110(3), 1581-1597. https://doi.org/10.1121/1.1391244
- Bickley, C., & Hunniccutt, S. (1992). Acoustic analysis of laughter. Proceedings of the International Conference on Spoken Language Processing, Vol. 2, pp. 927-930.
- Brown, M. J. E. (2001). Humoreske. In New Grove Dictionary of Music and Musicians (2nd ed.). (Vol. 11, pp. 836). New York, NY: Macmillan Publishers Limited. https://doi.org/10.1093/gmo/9781561592630.article.13549
- Bryant, G. A., & Aktipis, C. A. (2014). The animal nature of spontaneous human laughter. Evolution and Human Behavior, 35(4), 327-335. https://doi.org/10.1016/j.evolhumbehav.2014.03.003
- Gruneberg, R. (1969). Humor in music. Philosophy and Phenomenological Research, 30(1), 122-125. https://doi.org/10.2307/2105927
- Huron, D. (2004). Music-engendered laughter: An analysis of humor devices in PDQ Bach. In S. Lipscomb, R. Ashley, R.O. Gjerdingen, & P. Webster (Eds), Proceedings of the 8th International Conference on Music Perception and Cognition. Evanston, Illinois, 2004, pp. 700-704.
- Huron, D. (2006). Sweet Anticipation: Music and the Psychology of Expectation. Cambridge, Massachusetts: MIT Press. https://doi.org/10.7551/mitpress/6575.001.0001
- Jankélévitch, V. (1961). La Musique et l'Ineffable. France: Editions Armand Colin. Reprinted 1983, Paris: Editions du Seuil. Translated as Music and the Ineffable. (2003) by Carolyn Abbate. Princeton: Princeton University Press.
- Juslin, P. N., & Laukka, P. (2003). Communication of emotions in vocal expression and music performance: Different channels, same code? Psychological bulletin, 129(5), 770. https://doi.org/10.1037/0033-2909.129.5.770
- Kennedy, M. (n.d.). Humoresque (Fr.), Humoreske (Ger.). In The Oxford Dictionary of Music (2nd ed.). Oxford, UK: Oxford University Press. In Oxford Music Online. https://doi.org/10.1093/acref/9780199578108.001.0001
- Lasarcyk, E., & Trouvain, J. (2008). Spread lips + raised larynx + higher f0 = Smiled Speech? An articulatory synthesis approach. Proceedings of ISSP, 43-48.
- Lavan, N., Scott, S. K., & McGettigan, C. (2016). Laugh like you mean it: Authenticity modulates acoustic, physiological and perceptual properties of laughter. Journal of Nonverbal Behavior, 40(2), 133-149. https://doi.org/10.1007/s10919-015-0222-8
- Moore, R., & Johnson, D. (2001). Effects of musical experience on perception of and preference for humor in Western art music. Bulletin of the Council for Research in Music Education, 149(II), 31-37.
- Mull, H. K. (1949). A study of humor in music. American Journal of Psychology, 62, 560-566. https://doi.org/10.2307/1418560
- Mullin, C. A. (2010). International Music Score Library Project/Petrucci Music Library (review). Notes, 67(2), 376-381.
- Provine, R. R. (2000). Laughter: A Scientific Investigation. New York: Viking Penguin.
- Provine, R. R. (2008). Notation and expression of emotion in operatic laughter. Behavioral and Brain Sciences, 31(5), 591-592. https://doi.org/10.1017/S0140525X08005463
- Puckette, M., & Zicarelli, D. (1990). Max/Msp. Cycling, 74, 1990-2006.
- Schröder, M., Auberge, V., & Cathiard, M. A. (1998). Can we hear smile? In Fifth International Conference on Spoken Language Processing.
- Straub, N.C. (1998). Section V, The respiratory system. In: R.M. Berne & M.N. Levy (Eds), Physiology, 4th edition. Maryland Heights, Missouri: Mosby.
- Tartter, V. C. (1979). Grinning from ear-to-ear: The perception of smiled speech. Journal of the Acoustical Society of America, 65(S1), S112-S113. https://doi.org/10.1121/1.2016953
- Tartter, V. C. (1980). Happy talk: Perceptual and acoustic effects of smiling on speech. Attention, Perception, & Psychophysics, 27(1), 24-27. https://doi.org/10.3758/BF03199901
- Tartter, V. C., & Braun, D. (1994). Hearing smiles and frowns in normal and whisper registers. Journal of the Acoustical Society of America, 96(4), 2101-2107. https://doi.org/10.1121/1.410151
- Walton, K.L. (1993). Understanding humor and understanding music. Journal of Musicology, 11(1), 32-44. https://doi.org/10.2307/764150
- Wheelock, G. (1992). Haydn's Ingenious Jesting with Art: Contexts of Musical Wit and Humor. New York: Schirmer Books.
